لماذا سينهار نظام الـ RAG الخاص بك عند زيادة الضغط — والبنية المعمارية التي تمنع ذلك
تعمل معظم أنظمة الـ RAG بشكل ممتاز في العروض التوضيحية (demos). لكن تحت ضغط الاستخدام الفعلي المتزامن تنهار — حيث يرتفع زمن الاستجابة (latency)، وتتضخم فواتير الـ LLM، ويتخلى المستخدمون عن النظام. الحل ليس في استخدام نموذج أفضل، بل في فصل خطي المعالجة (pipelines) اللذين لا ينبغي لهما مشاركة البنية التحتية أبدًا.
يتكرر هذا النمط في كل مشروع RAG للمؤسسات نعمل عليه تقريبًا: يقوم الفريق ببناء مساعد معرفي، ويعمل بشكل رائع في بيئة التطوير (staging)، ويبهر العرض التوضيحي أصحاب المصلحة، ثم يتم إطلاقه للجمهور. بعد ثلاثة أسابيع، تمتلئ قناة الدعم الفني بالشكاوى حول البطء، ويتساءل المدير المالي عن سبب تضاعف فاتورة OpenAI ثلاث مرات، ويبدأ أحدهم في التخطيط بهدوء لإعادة بناء البنية المعمارية (re-architecture).
المشكلة ليست في النموذج (model) الذي اختاروه، ولا في قاعدة بيانات المتجهات (vector database). المشكلة هي أنهم قاموا ببناء خط معالجة (pipeline) واحد وتوقعوا منه القيام بمهمتين مختلفتين تمامًا في نفس الوقت.
المهمتان اللتان تعطلان بعضهما البعض
يقوم نظام الـ RAG في بيئة الإنتاج الفعلي بأمرين:
- ▸
إدخال البيانات (Ingestion) — أخذ المستندات، وتقسيمها إلى مقاطع (chunking)، وتوليد التضمينات (embeddings)، وكتابتها في قاعدة بيانات المتجهات. هذه العملية تستهلك موارد المعالج (CPU) وكارت الشاشة (GPU) بشكل مكثف، وغالبًا ما تكون بطيئة (قد يستغرق معالجة ملف PDF مكون من 500 صفحة حوالي 30 ثانية)، وليست حساسة للوقت.
- ▸
الاستعلام (Query) — استقبال سؤال المستخدم، وتوليده كتضمين، والبحث في قاعدة بيانات المتجهات، وتمرير السياق المسترجع (retrieved context) إلى الـ LLM، ثم إرجاع الإجابة. يجب أن تكتمل هذه العملية في أقل من ثانيتين لكي تكون مقبولة لدى المستخدمين.
عندما يعمل هذان المساران على نفس البنية التحتية، فإن قيام مستخدم واحد برفع مستند كبير يتسبب في تشبع الـ GPU (saturation event) يشعر به جميع المستخدمين الآخرين في نفس اللحظة. يرتفع زمن الاستجابة (latency) فجأة من 400 مللي ثانية إلى 4 ثوانٍ. وإذا كنت تدفع مقابل كل توكن (token) وكان النظام يقوم بعمليات إدخال بيانات كثيفة التضمين في الخلفية، فإن تكاليف الاستنتاج (inference) ستتضخم بشكل غير متناسب أيضًا.
هذه ليست مشكلة نموذج (model)، بل هي مشكلة بنية معمارية (architecture).
الحل: خطّا معالجة، يتم توسيع نطاقهما بشكل مستقل
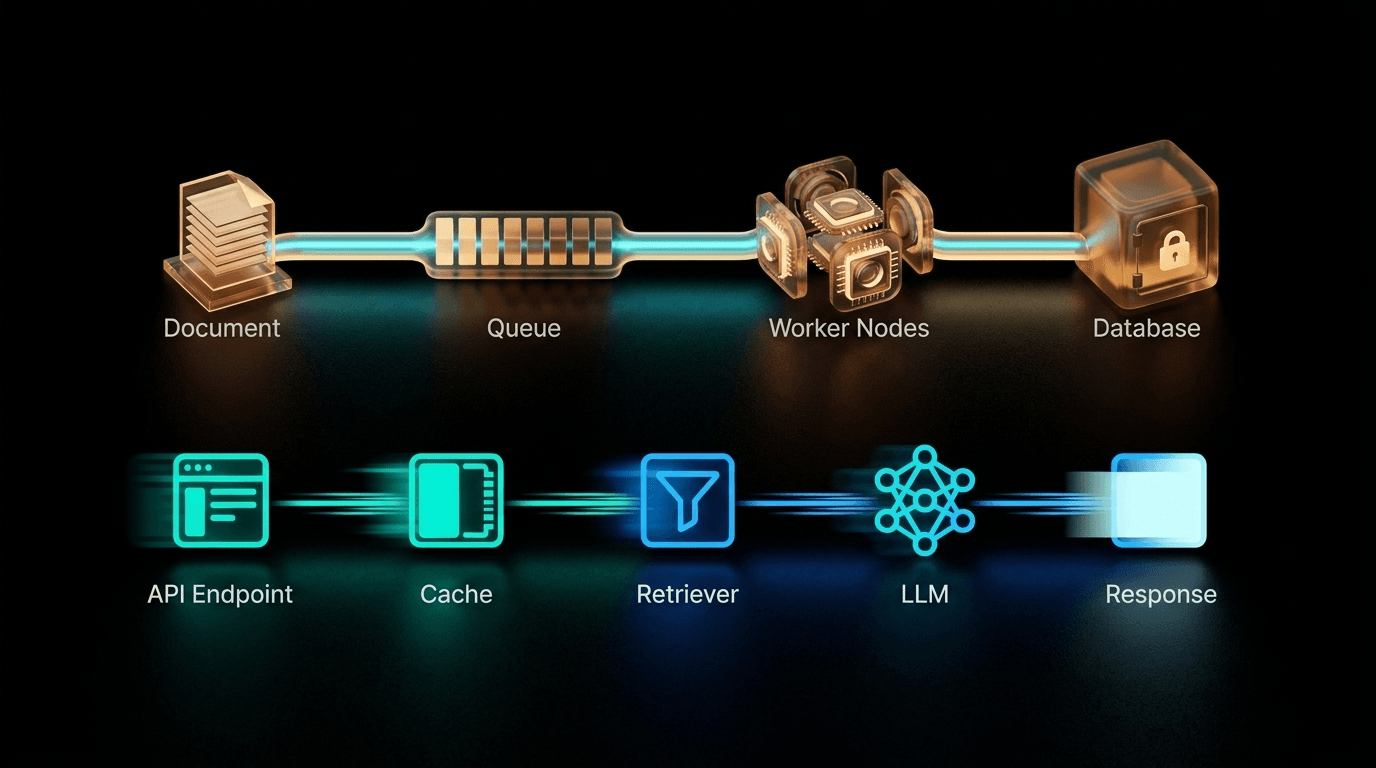
البنية المعمارية التي تتحمل ضغط الاستخدام الفعلي تفصل تمامًا بين خط معالجة الإدخال (ingestion) وخط معالجة الاستعلام (query) — موارد حوسبة مختلفة، وقواعد توسيع نطاق (scaling) مختلفة، وأنماط فشل منفصلة.
خط معالجة الإدخال: غير متزامن (async) وغير مرئي للمستخدمين
يؤدي رفع المستند إلى إرسال مهمة إلى طابور رسائل (message queue). تقوم برامج العمل (workers) بسحب المهام من الطابور في الخلفية، بينما يتلقى المستخدم تأكيدًا فوريًا بالاستلام ويستمر النظام في المعالجة بشكل غير متزامن.
المكونات الأساسية:
طابور الرسائل (Celery + Redis أو Kafka): يمتص الارتفاعات المفاجئة في عمليات الرفع. فعندما يقوم 10 مستخدمين برفع ملفات PDF بحجم 20 ميجابايت في نفس الوقت، فإنهم لا يتنافسون على موارد الـ GPU — بل ينتظرون في الطابور. ويتم معالجة كل مستند فور توفر worker متاح.
برامج العمل في الخلفية (Background workers): تتعامل مع المهام الكثيفة حوسبيًا: تحليل ملفات PDF، واستخراج النصوص، والتقسيم إلى مقاطع (chunking)، وتوليد التضمينات (embeddings). يمكن زيادة عدد هذه البرامج (scale up) في أوقات غير الذروة وتقليلها أثناء أوقات ذروة الاستعلامات.
تخزين التضمينات القائم على المحتوى (Content-addressed storage): قبل توليد التضمين، قم بعمل hash لمحتوى النص + معرف النموذج (model ID). إذا كان هذا الـ hash موجودًا بالفعل في قاعدة البيانات، فتخطى إعادة التضمين. وعندما تقوم بترقية نموذج التضمين وتحتاج إلى إعادة الفهرسة (re-indexing)، فإن المحتوى المتغير فقط هو ما سيتطلب حوسبة جديدة. في مجموعة مستندات تحتوي على 50,000 مستند، يمكن أن يقلل هذا من تكلفة إعادة الفهرسة بنسبة تتراوح بين 60% إلى 80%.
خط معالجة الاستعلام: المسار الذي لا يجب أن يتباطأ أبدًا
يمر كل طلب مستخدم عبر هذا المسار. زمن الاستجابة (latency) هنا هو المقياس الفعلي لجودة منتجك في نظر المستخدم. إليك التسلسل الذي يعمل بكفاءة تحت الضغط المتزامن:
</>View technical implementation · عرض التفاصيل التقنية
API Gateway → Semantic Cache → Query Rewriter → Hybrid Retriever → Reranker → LLM
لكل خطوة دور محدد، وتخطي أي منها سيظهر بوضوح في مؤشرات الأداء الخاصة بك.
المكون الأسرع في استرداد تكلفته: التخزين المؤقت الدلالي (Semantic Caching)
من بين جميع التحسينات في نظام RAG قيد التشغيل الفعلي، يحقق التخزين المؤقت الدلالي (semantic caching) أعلى عائد على الاستثمار (ROI) مقارنة بجهد التنفيذ. وإليك سبب أهميته من الناحية المالية.
في قواعد المعرفة الخاصة بالمؤسسات، تكون غالبية الاستعلامات عبارة عن صيغ مختلفة لمجموعة صغيرة من الأسئلة المتكررة. فسؤال "ما هي سياسة الاسترداد لدينا؟" قد يأتي بـ 50 صيغة مختلفة. وسؤال "ما هي متطلبات التأشيرة لـ [الدولة]؟" يطرحه مستخدمون مختلفون ويحصلون جميعًا على إجابات متطابقة.
يعمل التخزين المؤقت الدلالي على مستويين:
- ▸المطابقة التامة في Redis: إذا تكرر نفس نص الاستعلام تمامًا، يتم إرجاع الاستجابة المخزنة مؤقتًا على الفور. تكلفة الـ LLM هنا هي صفر.
- ▸التشابه الدلالي (Semantic similarity): إذا كان الاستعلام الجديد قريبًا دلاليًا من استعلام مخزن مؤقتًا (تشابه جيب التمام - cosine similarity فوق حد معين، عادةً بين 0.92 و0.95)، يتم إرجاع الاستجابة المخزنة. لقد وثق أحد فرق العمل في المؤسسات التي تعاملنا معها انخفاضًا بنسبة 50% في تكاليف واجهة برمجة تطبيقات الـ LLM بفضل هذه الطبقة الفردية فقط.
المقايضة هنا هي حداثة البيانات (freshness) — حيث يجب إلغاء صلاحية الاستجابات المخزنة مؤقتًا عند تغيير المستندات المصدرية. بالنسبة لقواعد المعرفة التي يتم تحديثها أسبوعيًا أو شهريًا، يمكن إدارة هذا الأمر بسهولة تامة. أما بالنسبة لمصادر البيانات الفورية (real-time)، فيجب تقليل وقت صلاحية التخزين المؤقت (TTL) أو إلغاؤه تمامًا.
لماذا لا يعد vLLM خيارًا ترفيهيًا عند وجود ضغط متزامن حقيقي
بمجرد أن يتجاوز عدد المستخدمين المتزامنين 10 إلى 15 مستخدمًا، تصبح طريقة تشغيل واستضافة الـ LLM (serving) بنفس أهمية النموذج الذي اخترته.
الطريقة الافتراضية التي تتبعها معظم الفرق لدمج الـ LLM (استدعاء واجهة برمجة تطبيقات أو تحميل نموذج باستخدام مكتبة transformers الأساسية) تعالج طلبًا واحدًا في كل مرة. تصطف الطلبات في طابور، حيث ينتظر المستخدم رقم 12 انتهاء المستخدمين من 1 إلى 11. وتحت الضغط المتزامن, يؤدي هذا إلى تراكم زمن الاستجابة (cascading latency) الذي يتزايد خطيًا مع زيادة الحمل — وهو بالضبط السيناريو الأسوأ.
يغير نظام التجميع المستمر (continuous batching) في vLLM هذا المفهوم تمامًا. فبدلاً من معالجة الطلبات بالتتابع، يقوم بملء دورات معالجة الـ GPU (forward passes) بطلبات متعددة متزامنة، مستغلاً الذاكرة التي كانت ستظل خاملة أثناء توليد التوكنز (tokens). النتيجة: معدل إنتاجية (throughput) يتزايد بشكل شبه خطي (sublinearly) مع الحمل بدلاً من التزايد الخطي المتسارع.
على كارت شاشة A100 بسعة 80 جيجابايت لتشغيل نموذج بحجم 14B بصيغة BF16، يستطيع نظام التجميع المستمر في vLLM معالجة حوالي 10,800 طلب في الساعة. بينما يصل كارت H100 إلى 14,400 طلب. قارن ذلك بحوالي 800 إلى 1,200 طلب فقط في الساعة يحققها الإعداد التقليدي للمعالجة المتتالية على نفس العتاد.
بالنسبة لـ الاستضافة الداخلية (on-prem) حيث تكون تكلفة العتاد ثابتة، يحدد هذا الفرق ما إذا كان نظامك يستطيع التعامل مع 10 مستخدمين متزامنين أو 80 مستخدمًا — على نفس الـ GPU.
خطأ الاسترجاع الهجين الذي يضخم الضوضاء في نتائج الـ top-K
ترتكب معظم الفرق التي تضيف خوارزمية BM25 إلى جانب البحث عن المتجهات (vector search) لتحقيق استرجاع هجين (hybrid retrieval) خطأً محددًا: وهو السماح لنتائج الكلمات المفتاحية بمنافسة النتائج الدلالية بحرية. فالمستند الذي يحتوي على نفس الكلمات الواردة في الاستعلام يظهر في مرتبة متقدمة حتى لو كان غير مرتبط دلاليًا بالسؤال الفعلي.
الحل: يجب أن تقوم خوارزمية BM25 فقط بزيادة ترتيب المقاطع (chunks) التي تجاوزت بالفعل الحد الأدنى من تشابه المتجهات (vector similarity threshold). يجب أن يكون المقطع ذا صلة دلالية أولاً قبل أن تمنحه مطابقة الكلمات المفتاحية أي وزن إضافي في الترتيب. بدون هذا الفلتر، ستؤدي أرقام العقود وأكواد المنتجات (التي تتعامل معها BM25 بشكل ممتاز) إلى جلب مقاطع تحتوي بالصدفة على تلك النصوص دون أن تقدم إجابة مفيدة.
هذا التغيير البسيط في الفلترة عادةً ما يحسن جودة الإجابات بشكل ملموس. وتشير الفرق التي طبقت هذا الحل إلى أن نموذج إعادة الترتيب (reranker) أصبح يبذل جهدًا أقل بكثير لتقديم نتائج ممتازة.
أرخص تحسين للبنية التحتية يمكنك القيام به في نظام RAG ذي حركة مرور عالية هو ضغط الموجّه (prompt compression). في إحدى الحالات الواقعية في بيئة الإنتاج، تم تقليل متوسط زمن الاستجابة (median query latency) من 9.87 ثوانٍ إلى 0.71 ثانية — وهو انخفاض بنسبة 91% — ببساطة عن طريق استبدال استرجاع السياق الكامل باسترجاع انتقائي يمرر فقط أكثر 3 إلى 4 مقاطع صلةً بدلاً من 10 إلى 15 مقطعًا. دون تغيير النموذج، ودون ترقية العتاد.
ماذا تعني هذه البنية المعمارية لميزانيتك
دعنا نضع أرقامًا ملموسة توضح سبب جدوى الاستثمار في البنية المعمارية:
| السيناريو | تكلفة الـ LLM الشهرية (10 آلاف استعلام/يوم) | زمن استجابة P95 |
|---|---|---|
| خط معالجة واحد تقليدي، بدون تخزين مؤقت | ~$9,300 | 4–12 ثانية تحت الضغط |
| خطوط معالجة منفصلة، بدون تخزين مؤقت | ~$9,300 | 800 مللي ثانية - ثانيتين |
| خطوط معالجة منفصلة + تخزين مؤقت دلالي | ~$4,200–$5,500 | 300 - 800 مللي ثانية |
| البنية الكاملة (خطوط معالجة + تخزين مؤقت + vLLM) | ~$4,200–$5,500 | 200 - 500 مللي ثانية |
إن الاستثمار في البنية المعمارية (والذي يتراوح عادةً بين 3 إلى 8 آلاف دولار كجهد هندسي إضافي مقارنة بالبناء التقليدي المبسط) يسترد قيمته من خلال تقليل تكاليف واجهة برمجة تطبيقات الـ LLM في غضون 3 إلى 6 أشهر في أي نظام يستقبل حركة مرور يومية ملموسة.
الاستثمار في البيانات الوصفية (Metadata) الذي تتجاهله معظم الفرق
يذهب حوالي 40% من الوقت الهندسي في نظام RAG المصمم جيدًا للمؤسسات إلى تصميم مخطط البيانات الوصفية (metadata schema). بينما تخصص معظم الفرق 5% فقط من وقتها لذلك.
البيانات الوصفية هي ما يتيح لك تصفية عملية الاسترجاع لتقتصر على المجموعة الفرعية الصحيحة من المستندات قبل تشغيل البحث الدلالي — وذلك حسب نوع المستند، أو القسم، أو النطاق الزمني، أو معرف العميل، أو التصريح الأمني، أو أي بعد آخر. بدونها، سيقوم كل استعلام بالبحث في كامل مجموعة المستندات الخاصة بك، وهو أمر بطيء ومكلف، وغالبًا ما يعيد نتائج غير ذات صلة من مستندات لا علاقة لها بالموضوع.
العائد العملي: إذا كان لديك 50,000 مستند ولكن أي استعلام مستخدم يجب منطقيًا أن يسترجع من بين 500 مستند منها فقط، فإن الفلترة الجيدة للبيانات الوصفية تقلل من مساحة البحث الفعلية بنسبة 99% قبل تشغيل عملية حسابية واحدة لتشابه المتجهات. هذا ليس تحسينًا هامشيًا — بل هو ما يجعل النظام يبدو فائق السرعة.
مشكلة عزل المستأجرين المتعددين (Multi-tenant isolation) في بيئات المؤسسات
إذا كنت تبني منتج RAG لعدة عملاء (أو لعدة أقسام لا ينبغي لأي منها الاطلاع على بيانات الآخر)، فيجب تصميم العزل كجزء أساسي من البنية التحتية منذ اليوم الأول.
يحتاج كل مستأجر (tenant) إلى:
- ▸مساحة اسم منفصلة (namespace) في قاعدة بيانات المتجهات (وليس مجرد فلتر — بل مساحة اسم حقيقية تمنع تسرب البيانات بين المستأجرين حتى في الحالات الاستثنائية).
- ▸مخازن مؤقتة منفصلة للتضمينات (حتى لا يتم إرجاع الاستجابات المخزنة لمستأجر ما إلى مستأجر آخر).
- ▸بيانات وصفية وسجلات وصول (access logs) معزولة تمامًا.
إذا كانت متطلبات الخصوصية صارمة للغاية، فقم بتشغيل نسخ منفصلة من النموذج (model instances) لكل مستأجر. هذا الخيار مكلف، ولكنه البنية الوحيدة التي تضمن عزلاً حقيقيًا وتامًا. وفي معظم الحالات، يوفر عزل مساحة الاسم (namespace isolation) مع الفلترة الصارمة للبيانات الوصفية حماية كافية.
الأسئلة الشائعة
ما هي التكلفة الإضافية التي تضيفها بنية RAG الصحيحة إلى مشروعك؟ تضيف الأنماط المعمارية الموضحة هنا — مثل طابور الإدخال غير المتزامن، والتخزين المؤقت الدلالي، والاسترجاع الهجين مع الفلترة — عادةً ما بين 4 إلى 10 آلاف دولار إلى تكلفة بناء نظام RAG مقارنة بالتنفيذ التقليدي ذي خط المعالجة الواحد. وتتراوح فترة استرداد هذه التكلفة عند معدل 5,000+ استعلام يوميًا بين شهرين إلى 4 أشهر من خلال توفير تكاليف واجهة برمجة تطبيقات الـ LLM وحدها.
عند أي حجم من الاستعلامات يصبح استخدام vLLM ضروريًا؟ بالنسبة لواجهات برمجة تطبيقات الـ LLM السحابية (مثل OpenAI و Anthropic)، لا ينطبق استخدام vLLM لأنك لا تتحكم في طبقة الاستضافة والتشغيل (serving). يصبح vLLM مهمًا عندما تقوم باستضافة الـ LLM ذاتيًا (self-hosting). أما بالنسبة للاستخدام السحابي، فإن التحسين المكافئ هو تجميع الطلبات (request batching) والتخزين المؤقت الدلالي. وبالنسبة للاستضافة الذاتية، يصبح vLLM ضروريًا بدءًا من 5 إلى 10 مستخدمين متزامنين فما فوق.
كيف يتم تنفيذ التخزين المؤقت للتضمينات القائم على المحتوى؟
قم بعمل hash للنص المدخل مدمجًا مع معرف نموذج التضمين (على سبيل المثال، SHA-256 لـ model_name + "::" + text). قم بتخزين الـ hash مقابل متجه التضمين (embedding vector) في Redis مع وقت صلاحية (TTL) طويل (أو بدون حد للصلاحية). قبل توليد التضمين، تحقق مما إذا كان الـ hash موجودًا؛ وإذا كان موجودًا، فقم بإرجاع التضمين المخزن مؤقتًا. هذه الطريقة قيمة للغاية أثناء دورات إعادة الفهرسة عندما يتغير النموذج ولكن تظل معظم المستندات كما هي دون تغيير.
هل يمكن أن يعيد التخزين المؤقت الدلالي إجابات خاطئة إذا لم يكن الاستعلام المخزن متطابقًا تمامًا؟ نعم، إذا كان حد التشابه (similarity threshold) منخفضًا جدًا. حافظ على حد التشابه الدلالي عند 0.92 أو أعلى للاستعلامات الواقعية (factual). أما بالنسبة للاستعلامات الحوارية أو الإبداعية، فإما أن تقوم برفع الحد أكثر أو تعطيل التخزين المؤقت الدلالي تمامًا لهذه الأنواع من الاستعلامات.
→ RAG مقابل الضبط الدقيق: الأداة المناسبة لمعرفة المؤسسات → تشغيل RAG في بيئة الإنتاج بذاكرة 6GB VRAM: نموذج Qwen3.5 4B + nomic-embed