AI for Business Leaders
What AI costs, what it returns, and how to decide — from a team that builds these systems for a living. Technical evaluators will find the full detail inside each article.

AI Receptionist for Gulf Clinics: What It Handles, What It Doesn't, and the ROI
A missed call is a lost booking. Here is the exact business case, cost breakdown, and production reality of deploying bilingual AI voice agents in UAE and Saudi clinics.
Read article
Building Deterministic Guardrails for Stateful Multi-Agent Systems
Multi-agent systems fail in production when autonomous loops consume budgets and crash pipelines. Learn how state-graph architectures mathematically prevent AI drift.

Building a RAG System on Arabic Documents: The Technical Reality in 2026
Standard enterprise search pipelines fail on Arabic documents because of tokenization bloat and morphological mismatches. Here is the architecture required to retrieve Arabic text accurately.

The End of Thin AI Wrappers: Why Investors and Buyers Demand Native AI Architectures
In 2025, 42% of companies abandoned most of their AI initiatives, often because they relied on thin wrappers. Here is why the B2B market now demands deep, workflow-integrated AI systems, and how to build them.

Arabic Voice AI for Clinic Booking: Achieving Sub-500ms Latency in Gulf Dialects
Why standard voice AI fails for Gulf clinics, and the exact pipeline required to process Khaleeji dialects and book appointments in under 500 milliseconds.

Navigating GCC Data Sovereignty: Deploying Enterprise AI On-Premise
Tightening data regulations in Saudi Arabia and the UAE mean public cloud APIs are no longer viable for sensitive data. Here is how to build compliant, on-premise AI.

AI Regulation Across the GCC: Saudi Arabia, UAE, and Qatar Compared (2026)
Operating AI across the Gulf requires navigating distinct regulatory frameworks. Compare the mid-2026 requirements for Saudi Arabia, the UAE, and Qatar to avoid compliance failures.

What LLM APIs Actually Cost at Scale: Retries, Context, and the Bills Nobody Budgets
The per-token price on a vendor's website is a fraction of your actual AI bill. True unit economics require accounting for context bloat, retry storms, and evaluation overhead.

Qdrant vs pgvector at 10M+ Vectors: What Actually Changes at Scale
pgvector is the right choice for an AI pilot, but scaling it past 10 million vectors forces expensive database upgrades. Here is the math on when to migrate to a dedicated engine.

Does ElevenLabs Scale for Real-Time Voice Agents? Latency, Cost per Minute, and the Limits
ElevenLabs provides the highest quality text-to-speech in the industry, but running it in real-time voice agents introduces strict latency, concurrency, and cost constraints. Here is the math for production scale.

PDPL Compliance for AI Systems: A Practical Checklist for Saudi and UAE Deployments
Cross-border inference calls to foreign LLM APIs often trigger unapproved cross-border data transfers. Here is the architecture checklist for deploying compliant AI systems in Saudi Arabia and the UAE.

Connecting an AI Assistant to Your EHR: What Clinic Chatbot Integration Actually Involves
Most clinic AI pilots fail because they treat EHR integration as a simple API connection. Production systems require read-only scoping, middleware orchestration, and strict data residency compliance.

AI Lead Qualification for Real Estate in Dubai: Responding First Without Hiring More Agents
In the Dubai property market, the first brokerage to reply to a WhatsApp inquiry wins the lead. Here is how to build production-grade AI agents that qualify buyers 24/7 in Arabic and English.

AI for Clinics in the UAE: What Actually Works in 2026
The direct answer for UAE clinic owners: AI reliably handles three jobs today - answering every phone call in Arabic and English, booking appointments into your calendar, and answering staff questions from your own protocols. What each costs, what it requires, and the data rules to respect.

Enterprise RAG vs Microsoft Copilot: An Honest Side-by-Side for IT Buyers
Microsoft Copilot is a personal productivity tool, while custom Enterprise RAG is an automated operational engine. Here is how to decide which AI architecture fits your business.

Saudi Arabia's AI Regulation in 2026: What the June SDAIA Package Actually Requires
Saudi Arabia has no standalone AI law yet - but the June 2026 SDAIA package of 10 regulatory documents, the binding PDPL, and sector rules from SAMA and SFDA already define what companies deploying AI in the Kingdom must do. A plain-language guide.

Semantic Routing in Production: Using LiteLLM to Slash Inference Costs
Sending every user prompt to a frontier model rapidly erodes your margins. Here is how production teams use semantic routing and LiteLLM to cut inference costs by up to 70% while improving latency.

When Your AI Agent Makes a Mistake: Failure Modes, Recovery, and Why This Is Solvable
AI agents will inevitably fail in production. The difference between a stalled pilot and a production system is whether that failure causes a silent business error or triggers a deterministic recovery loop.

The Death of Text-Only RAG: Why Multimodal Retrieval is the New Enterprise Standard
Traditional OCR pipelines often strip critical semantic context from enterprise documents. Multimodal RAG processes complex PDFs, charts, and tables natively, eliminating the extraction bottleneck.

HAAD-Compliant Voice AI for UAE Clinics: Architecture That Passes Regulatory Review
Off-the-shelf voice agents send patient data to overseas servers, often failing UAE healthcare compliance audits. Here is the architecture required to automate clinic calls without violating data sovereignty laws.

Navigating Gulf Data Sovereignty: The ROI of On-Premise AI in the UAE and Saudi Arabia
Strict enforcement of regional data laws makes relying on US-hosted LLMs a massive compliance risk. Here is the business case for deploying sovereign, on-premise AI.

RAG for Law Firms: Citations, Privilege, and Why On-Prem Is Non-Negotiable
Standard RAG systems hallucinate case law and risk waiving attorney-client privilege. Here is how to build production-grade legal AI that stays behind your firewall and cites its sources.

Enterprise AI Statistics 2026: The Numbers Behind Adoption, Failure, and the Gulf's Lead
A sourced, regularly updated reference of enterprise AI statistics for 2026: global adoption and failure rates, the buy-vs-build gap, and why the UAE and Saudi Arabia keep topping the charts. Every number links to its primary source.

Evaluating Multi-Agent Systems: Catching Tool-Use Hallucinations in Production
When AI agents use external tools, hallucinations stop being just bad text and become corrupted databases and spiked API bills. Here is how to evaluate and trace multi-agent trajectories before they fail.

Tool Use in Production LLMs: What Works, What Breaks, and What Nobody Warns You About
Connecting an LLM to your database or APIs looks easy in a demo. In production, unmanaged tool use leads to infinite loops, silent failures, and unpredictable API costs.

The End of the Thin Wrapper: Why AI SaaS Now Requires Deep Workflow Integration
B2B buyers are aggressively churning from simple prompt-wrapper applications. Defensible AI software now requires orchestrating complex, multi-tool workflows.

AI for Egyptian E-Commerce: Why Arabic Product Understanding Changes Everything
Standard AI models fail on Egyptian dialects and inflate API costs by nearly 3x due to tokenization inefficiencies. Here is how production-grade Arabic AI agents fix search abandonment and automate customer support.

The Gulf AI Mandate: Navigating Data Sovereignty and Local LLMs in the UAE and KSA
Strict data localization laws in the GCC are forcing enterprises to re-evaluate cloud AI APIs. Here is the cost and architecture required to run production-grade AI on-premise.

AI Automation for E-Commerce: 5 Workflows That Pay Back in 60 Days
Most e-commerce AI projects stall as basic chatbots. Here are five production-grade AI workflows that directly reduce OPEX and drive a 60-day ROI.
Agent Evals in Production: Tracing Tool Use and Trajectories
Traditional single-turn RAG evaluations fail in multi-agent systems. Discover how tracing agent trajectories and evaluating intermediate tool use prevents compounding errors and silent failures in production.

Human-in-the-Loop AI Agents: Building Systems People Actually Trust
Fully autonomous AI agents fail in high-stakes environments. Here is how to engineer human-in-the-loop systems that pause, request approval, and resume without breaking state.

The Death of Traditional IVR: Why Native Speech-to-Speech AI is Taking Over
Traditional phone trees and slow, robotic AI voice bots cost businesses millions in abandoned calls. Sub-300ms voice AI has finally made automated phone support viable for the enterprise.

The Gulf AI Talent Gap: Why MENA Companies Need External Engineering Partners Right Now
Gulf enterprises are spending millions on internal AI teams, only to end up with brittle demos and abandoned pilots. Here is why the regional talent shortage forces a shift to external production studios.

AI Data Sovereignty in the GCC: Deploying Compliant On-Premise LLMs
With stricter enforcement of the Saudi PDPL and UAE data laws, Gulf enterprises can no longer rely on US-hosted LLM APIs for sensitive internal documents. Here is the architecture and economics of deploying compliant, on-premise AI.

AI Lead Qualification for Gulf Real Estate: What the Agent Does on Every Inquiry
Most real estate brokerages waste their top performers on basic lead qualification. Here is the exact architecture and math behind an AI agent that qualifies Gulf real estate inquiries in Arabic and English.

Arabic NLP in Production 2026: What Works, What Doesn't, and What Nobody Admits
Most Arabic AI systems in the Gulf are English pipelines wearing a mask. Here is the technical reality of why standard RAG fails on Arabic data, and how to build production systems that actually work.

Beyond Vibe Checks: CI/CD Pipeline Architecture for Multi-Agent Systems
Traditional software testing fails when applied to non-deterministic AI agents. Here is how to architect continuous integration pipelines that evaluate agent reasoning, catch regressions, and protect production revenue.
Healthcare AI in the Gulf: Clinic Automation That Passes Regulatory Review
Deploying AI in Gulf healthcare requires navigating strict data residency laws and high patient expectations. Here is how to build regulatory-compliant clinic automation that actually works in production.
AI in Saudi Arabia: Vision 2030 Goals vs the Real Implementation Challenges in 2026
Saudi enterprises are under immense pressure to deliver on Vision 2030 AI mandates. Here is why generic Western models and slide-deck consultancies fail local operations, and how to build compliant, high-performing systems.

The Cost of 'Vibes-Based' AI: How to Measure and Guarantee LLM Accuracy in Production
Moving past 'vibes-based' testing is the only way to save your AI budget. Here is how we build quantitative evaluation pipelines that turn unpredictable LLM outputs into verifiable business metrics.

AI Agents for Legal: Research Brief to Contract Review Without Hallucinations
Discover how production-grade AI agents automate complex legal research and contract review without the risk of hallucinations or compliance failures.

LangGraph vs CrewAI vs AutoGen: The Production Comparison Nobody Publishes
An unvarnished engineering comparison of the three leading agent frameworks based on shipping real systems under production load. Discover why state machines beat chat rooms every time.

Scaling Voice AI to 1,000 Concurrent Calls: Integrating Deepgram Nova-3, ElevenLabs Flash, and WebRTC
Scaling real-time voice agents past a dozen concurrent calls causes massive latency spikes and audio jitter. Here is the production architecture to scale to 1,000 concurrent sessions using WebRTC, Deepgram Nova-3, and ElevenLabs Flash.

MCP Is the USB Port for AI Agents — Here's What That Means in Production
Model Context Protocol became the default AI tool interop standard in 2025. Every serious agent stack uses it now. Here's what it actually is, what it solves, and how we wire it into production LangGraph systems.

Why We Deploy AI Systems on Modal Instead of AWS Lambda
Serverless GPU changed what's economically viable for production AI. Cold-start under 1 second, pay per millisecond of GPU time, scale to zero — Modal makes inference infrastructure a non-issue for mid-market AI systems.

Multi-Agent vs Single-Agent: When the Architecture Complexity Actually Pays
Stop building multi-agent systems for simple sequential tasks. We dissect the latency, cost, and reliability trade-offs to show you exactly when to split your state.

How We Scope AI Agent Projects: The Method Behind the Fixed Price
AI agent projects fail because teams scope them like traditional CRUD apps. Here is the exact mathematical framework we use to price, bound, and build production-grade agent systems on a fixed budget.

AI Agent Development for SaaS Products: What Actually Ships
Stop building brittle wrappers that break under concurrent load. Here is the exact architectural blueprint, tech stack, and cost control framework we use to ship production-grade AI agents into SaaS workflows.

Composio: How We Connect AI Agents to 250+ Business Tools Without Writing Boilerplate
The integration problem kills more agent projects than bad LLM prompts. OAuth, rate limits, schema wrangling — it takes weeks per tool. Composio solves this with a managed layer for every tool your agent needs.

Exa vs Google Search API: Why Semantic Search Changes What AI Agents Can Do
Keyword search returns noise. Semantic search returns intent. When you're grounding AI agents in real-world data, that difference determines whether your agent produces useful output or confidently wrong answers.

Firecrawl for Enterprise RAG: Turning Websites and Docs Into Clean Knowledge Bases
The hardest part of RAG isn't retrieval — it's ingestion. Custom scrapers always break in production. Firecrawl solves the data layer so you can focus on the retrieval architecture.

Daft Is What Pandas Should Have Been for AI Data Pipelines
Most RAG and ML pipelines use Pandas or custom scripts for data prep. At scale, this breaks. Daft is a Rust-native distributed dataframe engine built for AI workloads — multimodal, GPU-aware, and petabyte-capable.
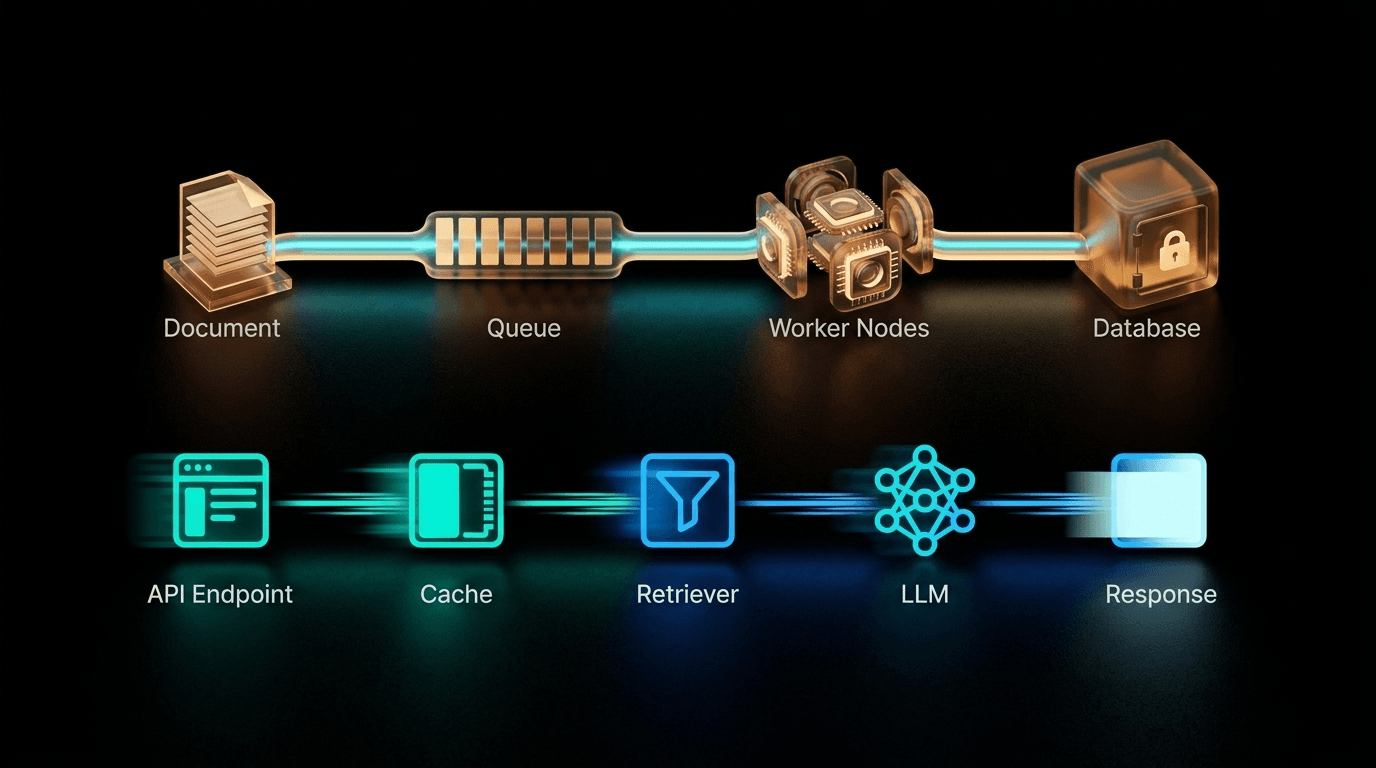
Why Your RAG System Will Break at Scale — And the Architecture That Prevents It
Most RAG systems work fine in demos. Under real concurrent load they collapse — latency spikes, LLM bills explode, users abandon. The fix isn't a better model. It's separating the two pipelines that should never share infrastructure.

n8n vs Custom AI Agents: How to Choose Before You Spend the Money
n8n is now a $2.5B company with 230,000 active users. It handles a lot of automation well and cheaply. But there's a class of problems where it hits a wall — and building on top of it when you need custom agents wastes months. Here's the honest framework.

On-Prem LLM Speed: How to Get 3× More Throughput Without Buying New Hardware
If your self-hosted LLM feels slow, the bottleneck is almost never the model. It's the serving stack around it. The right inference engine alone can triple your throughput. Here's the hierarchy of levers, with real benchmark numbers.
OpenClaw Has 310K Stars. What Personal AI Agents Mean for Your Business.
OpenClaw went from 0 to 310,000 GitHub stars in 4 months. It's a personal AI agent that runs locally, reads your files, and actually does things. The enterprise question isn't whether this technology works — it's what happens when your employees start using it without you.
2026 AI Trends That Will Actually Affect Your Budget — Not Just Your LinkedIn Feed
Most '2026 AI trends' articles are lists of things to be impressed by. This one is about what's actually happening in enterprise AI deployments right now, why it matters to your bottom line, and where the opportunities are before they become obvious.

Why Your AI Proof of Concept Fails in Production — The 12 Things We Fix Every Time
Most enterprise AI projects clear the POC stage. Most fail between POC and production scale. The same 12 problems appear on almost every engagement we take over. Here's what they are, why they happen, and what each one costs you if ignored.

RAG vs Fine-Tuning for Enterprise AI: When to Use Each (2026 Framework)
When to use RAG vs fine-tuning, answered directly: start with RAG for facts, citations, and changing knowledge; fine-tune only for reasoning patterns, style, and structured output - and only with 10K+ curated examples. The full decision framework with real costs.

LangGraph Development: 5 Patterns for Production-Safe Agents
The patterns that separate agents that work in demos from agents that survive real users: state checkpointing, human-in-the-loop gates, retry budgets, tool error handling, and observability hooks.

How to Build Voice AI Under 500ms End-to-End
A detailed breakdown of the streaming pipeline: Deepgram Nova-3 for STT, LLM with first-token streaming, ElevenLabs Flash for TTS, and how to pipeline them so the caller hears a response before the LLM finishes generating.

Production RAG on 6GB VRAM: Qwen3.5 4B + nomic-embed
Running a production-capable local RAG stack on a single 6GB VRAM GPU. Qwen3.5 4B at Q4_K_M quantization delivers 25–40 tok/s. nomic-embed-text at 274MB handles embeddings. Full setup, benchmarks, and caveats.

How Much Does It Cost to Build an AI Agent System?
A frank breakdown of what drives project cost: agent complexity, integration depth, LLM selection, hosting model, and ongoing costs. With real ranges from actual projects.

The Arabic AI Gap: Why the Gulf Has Almost No Quality AI Engineering
The MENA AI market is growing fast, but almost no AI studio offers bilingual Arabic/English capability at quality scale. What this gap means for Gulf businesses and for vendors who move first.
Building an AI system? Let's talk architecture.
Book a Free Architecture Call →